為什么增加解釋變量會使r2增加(R數據分析:工具變量回歸的做法和解釋,實例解析)
什么是工具變量,以及什么是孟德爾隨機化,以及孟德爾隨機化怎么實現都給大家寫了(大家去翻翻之前的文章呀),因為孟德爾隨機化的工具變量是基因變量,所以我們會用專門的R包去做,普通的工具變量研究,我們要用的方法又不一樣了。
我們做工具變量回歸的時候用的方法叫做兩階段最小二乘估計--two-stage least squares (TSLS),本文會給大家介紹該方法的原理和實際操作方法,希望能對大家有幫助。
兩階段最小二乘估計的基本原理
以下一步步給大家捋捋哈,假設我現在對學歷和收入這兩個變量有興趣,我想知道學歷在多大程度上影響了我們的收入,于是我把收入作為因變量,學歷作為自變量做個回歸:
y = α + βx + ε
弄個β出來,這個β能代表學歷對收入的影響嘛?不行。
因為你根本就沒考慮其它可能和x有關同時又影響y的因素,比如學歷高的人通常家境好,社會資源好,敢創新,肯鉆研等等,這些優秀的品質都有可能影響收入。但是我提到的這些變量你都沒有收集,或者就算你收集了你其實也是沒法控制的。
此時,我去找一個學歷的工具變量(這個工具變量和x強相關,但和之前提到的各種混雜無關,也絕不會影響y)。然后有學者就找了吸煙這個工具變量,具體參考下面的文獻:
Dickson, M. (2013). The causal effect of education on wages revisited. Oxford Bulletin of Economics and Statistics, 75(4), 477-498.
其中的基本思想就是通過工具變量切斷自變量和殘差的關系,解決內生性問題和反向因果,得到更加準確的自變量系數估計(大家要明白完美的工具變量是很難找得到的)。
到這兒,為啥要用,用啥兩個問題解決了,我們接下來看怎么用工具變量,或者說怎么做工具變量回歸(兩階段最小二乘估計):

兩階段最小二乘估計分為兩個階段,第一階段是將自變量的變異分解,分解成只有工具變量解釋的部分和與殘差相關的部分,在我們的例子中就是將學歷的變異分解成吸煙解釋的部分和相應的殘差,如下:
學歷 = c + d*(吸煙) + v
這個方程是明確工具變量對自變量的作用(在之前孟德爾隨機化的文章中一直用的是“暴露”這個詞,一個意思哈),這兒要求我們的系數d一定需要顯著(否則吸煙就不算是一個合格的工具變量),然后我們會將工具變量對自變量的預測值,作為第二階段的自變量。
第二階段就是用工具變量對自變量的預測值來估計回歸系數:
收入= α + β*學歷預測值 + ε(此處應該是學歷“拔”哈,工具變量預測的學歷。)

這一階段估計出來的系數β就是我們需要的啦,這個例子中,我們是只有一個內生變量---學歷和一個工具變量----吸煙的,這種情況叫做just identified,我們還可以多找幾個工具變量使得工具變量的數量大于內生變量的數量,此時就叫做 over-identified
實例操練
做兩階段最小二乘估計我們需要用到的函數是ivreg(),這個函數需要設置兩個部分的參數,基本形式是:y ~ x1 + x2 | x1 + z1 + z2
其中x1和 x2是外生和內生解釋變量,然后是一個豎杠,豎杠的右邊就放的是解釋變量,這兒需要注意的是在我們的解釋變量x1也是需要放在右邊一個的,如果外生變量很多的話,可以再寫一個豎杠,形成外生|內生|工具變量的公式形式。
比如,我現在想要研究學歷和收入的關系,我的數據如下圖:
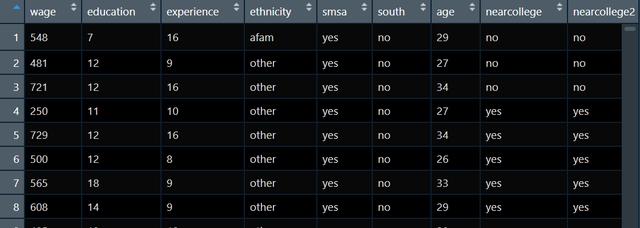
既有學歷education還有收入wage,當然還有很多的協變量。
要研究學歷如何影響了收入,普通來講我就做個回歸,把協變量加一加,甚至說加個二次項擬合得更好一點:
m_ols <- lm(log(wage) ~ education + poly(experience, 2) + ethnicity + smsa + south, data =data)summary(m_ols)看輸出:
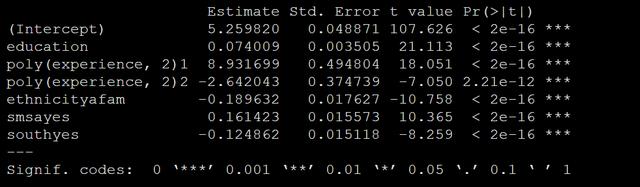
哦,似乎是學歷或者教育可以提升收入0.074個單位的log收入哦,這個對嗎?
并不對的,因為還有很多影響收入的變量你始終難以完全考慮或者說我這個數據中根本就沒有,還有你的自變量的內生性問題,反向因果造成的問題等等都會影響我們的系數,這個時候我就找了個工具變量nearcollege想做工具變量回歸,于是我就可以寫出如下的代碼:
m_iv <- ivreg(log(wage) ~ education + poly(experience, 2) + ethnicity + smsa + south | nearcollege + poly(age, 2) + ethnicity + smsa + south, data = SchoolingReturns)或者如下的代碼:
m_iv <- ivreg(log(wage) ~ ethnicity + smsa + south | education + poly(experience, 2) | nearcollege + poly(age, 2), data = data)在上面的代碼中第一種寫法是將外生和內生解釋變量寫一起然后再寫工具變量,第二種寫法是先寫外生再寫內生再寫工具變量,兩個寫法的輸出都是一樣的,注意雖然是兩階段最小二乘回歸,但是在實際操作中都是在ivreg這一個函數中就可以完成的,結果見下圖:
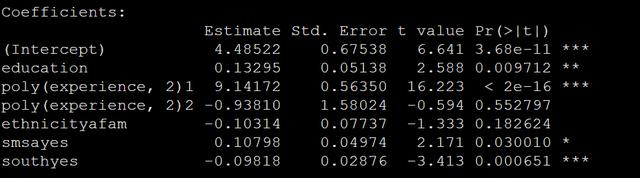
從結果中就可以看得出來,我們用兩階段最小二乘估計得到的系數是要大一點點的。
另外我們的結果中還有輸出模型的診斷信息:
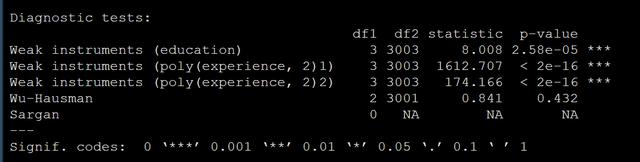
診斷信息中包含3個檢驗一個是weak instruments,一個是Wu–Hausman test,還有一個Sargan test,一個一個給大家寫寫是什么意思:
weak instruments:這個是檢驗我們的工具變量是不是一個好的工具變量,原假設是weak,所以我們希望這個統計量越大越好,p越小越好。
Wu–Hausman test:這個是檢驗內生性的,就是檢驗我們的自變量是不是和殘差有關。無關的話你直接做回歸就行。
Sargan test:這個檢驗只有在工具變量的個數超過內生變量的個數的時候才有,如果這個檢驗顯著的話就說明至少有一個工具變量是不行的。
小結
今天給大家寫了工具變量回歸的做法和解釋,感謝大家耐心看完,自己的文章都寫的很細,代碼都在原文中,希望大家都可以自己做一做,請關注后私信回復“數據鏈接”獲取所有數據和本人收集的學習資料。如果對您有用請先收藏,再點贊轉發。
也歡迎大家的意見和建議,大家想了解什么統計方法都可以在文章下留言,說不定我看見了就會給你寫教程哦,另歡迎私信。
如果你是一個大學本科生或研究生,如果你正在因為你的統計作業、數據分析、論文、報告、考試等發愁,如果你在使用SPSS,R,Python,Mplus, Excel中遇到任何問題,都可以聯系我。因為我可以給您提供好的,詳細和耐心的數據分析服務。
如果你對Z檢驗,t檢驗,方差分析,多元方差分析,回歸,卡方檢驗,相關,多水平模型,結構方程模型,中介調節,量表信效度等等統計技巧有任何問題,請私信我,獲取詳細和耐心的指導。
If you are a student and you are worried about you statistical #Assignments, #Data #Analysis, #Thesis, #Reports, #Composing, #Quizzes, Exams.. And if you are facing problem in #SPSS, #R-Programming, #Excel, Mplus, then contact me. Because I could provide you the best services for your Data Analysis.
Are you confused with statistical Techniques like z-test, t-test, ANOVA, MANOVA, Regression, Logistic Regression, Chi-Square, Correlation, Association, SEM, multilevel model, mediation and moderation etc. for your Data Analysis...??
Then Contact Me. I will solve your Problem...
往期精彩
R數據分析:再寫stargazer包,如何輸出漂亮的表格
R數據分析:ROC曲線與模型評價實例
R數據分析:用R語言做潛類別分析LCA
R數據分析:用R語言做meta分析
R數據分析:使用R語言進行卡方檢驗
R數據分析:如何用R做驗證性因子分析及畫圖,實例操練
R數據分析:工具變量回歸與孟德爾隨機化,實例解析