stata做logit分析詳解(【計量分析系列】Stata應用:隨機參數logit、潛類別logit模型)
1、離散選擇模型
條件logit模型和混合logit模型均可以理解為多項式logit模型的特殊形式,且均是基于隨機效用與效用最大化的理論假設的離散選擇模型,而隨機參數logit與潛類別logit模型均由多項式logit模型演化而來。多項式logit模型是整個離散選擇模型體系的基礎,并且是最簡單的多元離散選擇模型形式。而多項式logit模型的本質是二元logit模型組,例如,M元的多項式logit模型其實就是(M-1)組二元logit模型。
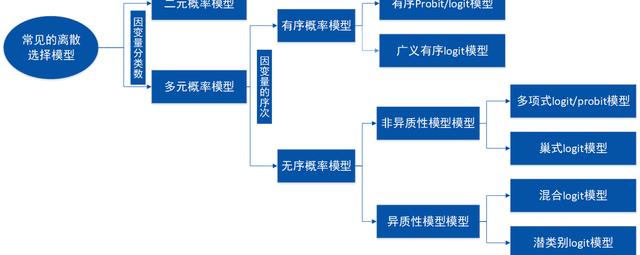
上圖簡要總結了一些常見的離散選擇模型,而異質性模型除了上圖所示外,還包括隨機參數概率模型、潛類別概率模型、隨機參數潛類別概率模型、馬爾科夫轉換模型以及隨機參數或潛類別馬爾科夫轉換模型。下表總結了各種異質性選擇模型的優缺點:

每個異質性模型均有自身的優點與缺點,即不存在一個最優的異質性模型。隨著模型越來越復雜,模型的優點隨之越多,與此同時模型缺點也隨之增多。在隨機參數概率模型中,混合logit模型是最常用的異質性模型;在潛類別概率模型中,潛類別logit模型是最常用的異質性模型。因此,本文的異質性模型只介紹隨機參數logit模型和潛類別logit模型。關于條件logit模型、混合logit模型、隨機參數logit模型以及潛類別logit模型的詳細介紹可以查閱文末的參考文獻(Train K.,2009)。離散選擇模型有許多的應用,包括:
研究出行選擇行為(選擇何種交通方式出行)
研究消費者商品選擇行為(選擇購買何種商品)
研究顧客的滿意度(滿意度的影響因素)
研究某種事物的接受度
產品的市場份額估計
支付意愿及選擇偏好
2 數據描述及研究步驟
2.1 數據描述
我們通過stata官方手冊中隨機參數logit模型的inschoice.dta來應用條件logit模型、混合logit模型、隨機參數logit模型、潛類別logit模型。該數據集包含6個變量用于記錄250人的可用保險計劃和選定計劃的信息,各變量的描述如下:
id:用于識別個體
premium:保費(隨方案而變),Insurance premium (in $100/month)
deductible:免賠額(隨方案而變),Deductible (in $1,000/year)
income:收入(個人屬性),Income (in $10,000/year)
insurance:保險方案(可選方案),Insurances
choice:選定的保險方案(因變量),Chosen alternative
首先,我們看一下數據前10行的格式:
. list in 1/10, sepby(id) abbreviate(10)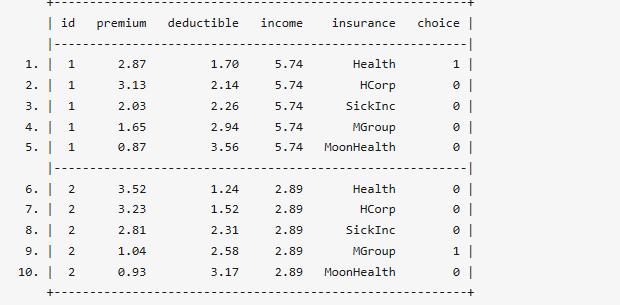
然后,查看下數據的基本特征:
. sum id premium deductible income insurance choice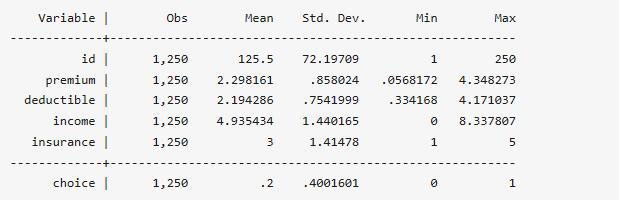
2.2 研究步驟
本文主要目的是通過inschoice.dta介紹stata估計混合logit模型、潛類別logit模型和隨機參數logit模型的方法,同時為了做對比,也將估計條件logit模型,具體流程如下:
估計條件logit模型;
估計混合logit模型;
估計隨機參數logit模型;
在估計潛類別logit模型。
3 應用實例
3.1 條件logit模型
由于條件logit模型只接受隨方案而變的自變量,因此僅使用 premium、deductible變量分析其對選擇保險方案的影響。此外,數據集本身沒有設置各方案的虛擬變量,故第一步先生成各保險方案的虛擬變量:
gen Health=0gen HCorp=0gen SickInc=0gen MGroup=0gen MoonHealth=0replace Health=1 if insurance==1replace HCorp=1 if insurance==2replace SickInc=1 if insurance==3replace MGroup=1 if insurance==4replace MoonHealth=1 if insurance==5然后,進行條件logit模型回歸,以方案5(MoonHealth)為參考類別:
. clogit choice Health HCorp SickInc MGroup premium deductible,group(id) nolog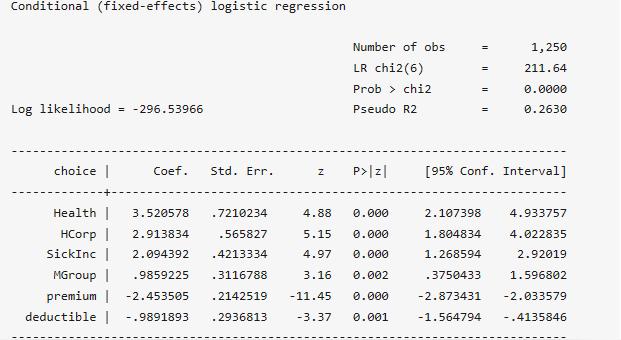
從估計的結果可以看出,如果其他解釋變量的取值相同(premium、deductible),則個人最有可能選擇Health保險方案。另外,一個方案的保費和免賠額越高,則選擇該方案的概率越低。由于離散選擇模型是非線性模型,故模型的系數只有其符號能反映正負影響,而不能反映影響的大小,所以在上述命令中加入OR計算其風險比:
. clogit choice Health HCorp SickInc MGroup premium deductible,group(id) nolog or
premium的風險比為0.086,表示一個方案的保費每增加一個單位(100美元),則選擇該方案的概率將會降低91.4%。此外,如果各方案的保費和免賠額相等,則個人選擇Health保險方案的概率是MoonHealth的33.804倍,其他變量可以類似的解釋。
3.2 混合logit模型
相比于條件logit模型只接受隨方案而變的變量,混合logit還可以接受個人屬性變量,為了進行對比,先進行僅包含隨方案而變的混合logit模型。同樣,以方案5(MoonHealth)為參考類別:
. asclogit choice premium deductible,case(id) alternatives(insurance) base(5) nolog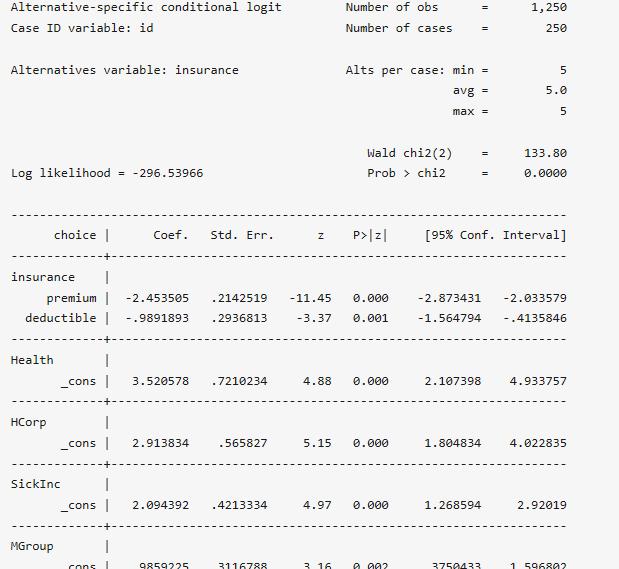
通過對比條件logit模型和混合logit模型的結果,可以發現當僅包含隨方案而變的自變量時,混合logit模型和條件logit模型的估計結果一致。下面,在上述混合logit模型的基礎上加入個人屬性變量(income),并計算各變量的風險比:
asclogit choice premium deductible,case(id) alternatives(insurance) base(5) casevars(income) nolog or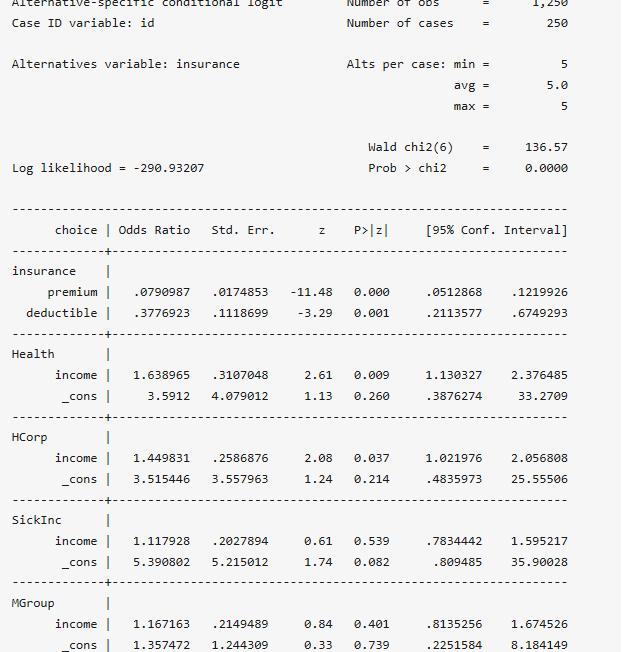
結果顯示,收入(income)對選擇Health和HCorp方案的選擇在0.05水平上有影響。例如年收入每增加一個單位(10,000美元),個人選擇Health保險方案的概率將提高64%。
3.3 隨機參數logit模型
隨機參數logit模型假設個體之間存在異質性,通過模型參數的分布(均值、標準差)刻畫個體的異質性。stata15.0提供了asmixlogit命令用于估計隨機參數logit模型,新的stata16.0版本采用了新命令cmmixlogit作為官方命令,故本文采用cmmixlogit估計隨機參數logit模型。首先通過smset設置個體和可選方案變量,本數據集為id和insurance變量,命令:
. cmset id insurance
假定premium與deductible均為隨機參數,并且假定參數服從正態分布;此外,隨機參數logit模型是采用蒙特卡羅模擬法估計參數的,研究表明使用蒙特卡羅法時采用Halton序列抽樣更有效率,故本文采用Halton序列抽樣法進行演示,并設定每次Halton序列取1000個點,命令如下:
. cmmixlogit choice, random(deductible premium) casevars(income) basealternative(5) intmethod(Halton) intpoints(1000)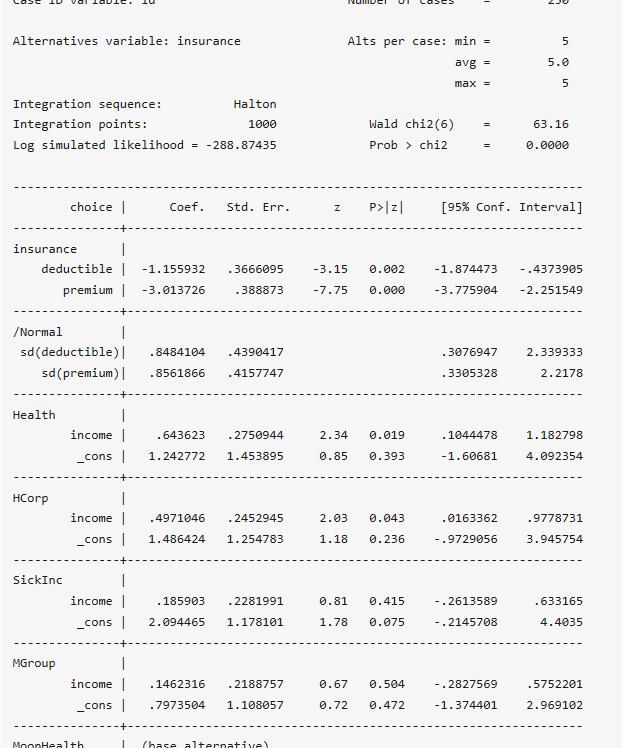
stata提供的檢驗關于是否需要采用隨機參數的方法比較保守,僅作為參考。實際上,判斷是否需要采用隨機參數logit的方法很簡單,只需要看隨機參數的均值和標準差是否顯著即可。stata官方命令計算的結果僅提供隨機參數均值的Z和P值,并不提供其標準差的顯著性統計量。我們可以很簡單的計算出其Z統計量(Z統計量=估計值/標準差):

過計算出的Z值可以看出,premium的標準差在0.05顯著性水平上顯著,deductible的標準差在0.1的顯著性水平上顯著,表明考慮將這兩個變量刻畫成隨機參數是合理的。隨機參數logit模型的固定參數估計解釋跟前述模型一致,故這里只以deductible為例,介紹下如何解釋隨機參數。deductible服從N( -1.155932, 0.8484104^2)的正態分布,根據正態分布的累計概率計算結果表明,一個方案的免賠額越高,91.31%的個體選擇該方案的概率更低,而8.69%的個體選擇該方案的概率更高,這體現了個體之間的異質性。
同樣地,我們也可以計算每個變量的邊際效應,以定量衡量各變量對選擇各方案的邊際效應,以deductible為例,首先預測每個保險方案的市場份額:
. margins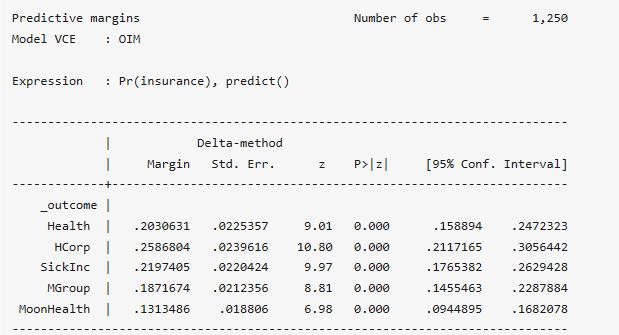
結果表明,根據本身的數據集預測有20.3%的個體選擇Health保險方案。然后通過改變deductible的值,以考察選擇Health保險方案份額的變化,考慮將deductible增加10%:
. margins, at(deductible=generate(deductible*1.10)) alternative(Health)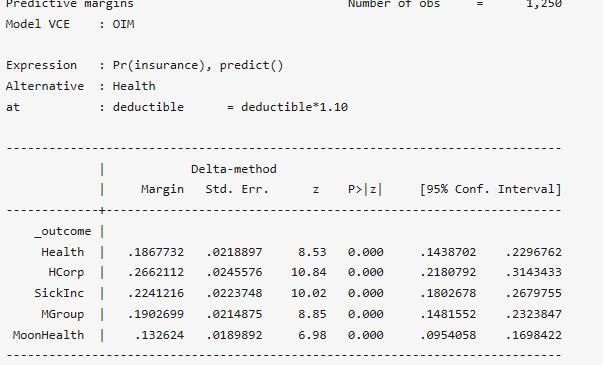
我們可以發現,當deductible增加10%,選擇Health保險方案的個體降至了18.7%。
注:本例只是為了演示作用,簡單的估計了隨機參數logit模型,在實際應用中需要多次測試隨機參數服從的不同的分布形式、以及不同抽樣序列的樣本點值。尤其是當變量數多了以后,需要多次測試每個變量是否可以建模為隨機參數。此外,Nlogit軟件也可以估計隨機參數logit模型,并且比stata更靈活,可以自己寫效用函數,甚至可以估計非線性效用函數,也可以將個人屬性變量的參數估計刻畫成隨機參數,有興趣的讀者可以采用Nlogit軟件試試,文末會給出Nlogit軟件的參考文獻和書目。
3.4 潛類別logit模型
Pacifico's (2012)寫了個用EM算法估計潛類別logit模型的外部命令(lclogit),本文也將采用lclogit命令估計潛類別logit模型,使用該命令前需要先安裝,這里就不演示命令安裝過程了。由于潛類別logit模型事先不知道最佳的潛類別數,故在正式估計模型前,需要根據不同類別數的CAIC和BIC指標確定合適的潛類別數。因此,先運行以下命令,確定合適的潛類別數:
. forvalues c = 2/5 { lclogit choice premium deductible,group(id) id(id) nclasses(`c') membership(income) seed(123) matrix b = e(b) matrix ic = nullmat(ic) \ `e(nclasses)', `e(ll)', `=colsof(b)', `e(caic)', `e(bic)'}matrix colnames ic = "Classes" "LLF" "Nparam" "CAIC" "BIC"matlist ic, name(columns)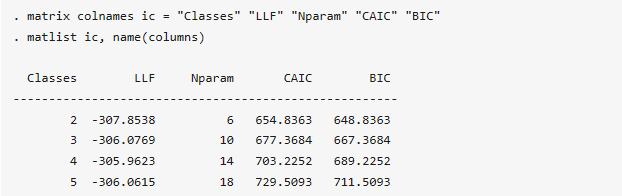
結果顯示,當類別數為2時,CAIC和BIC指標均達到最小,故應選取2個類別的潛類別logit模型。并且在上述模型的基礎上,加入方案的虛擬變量,下面將估計2類別潛類別logit模型:
. lclogit choice Health HCorp SickInc MGroup premium deductible,group(id) id(id) nclasses(2) membership(income) seed(123)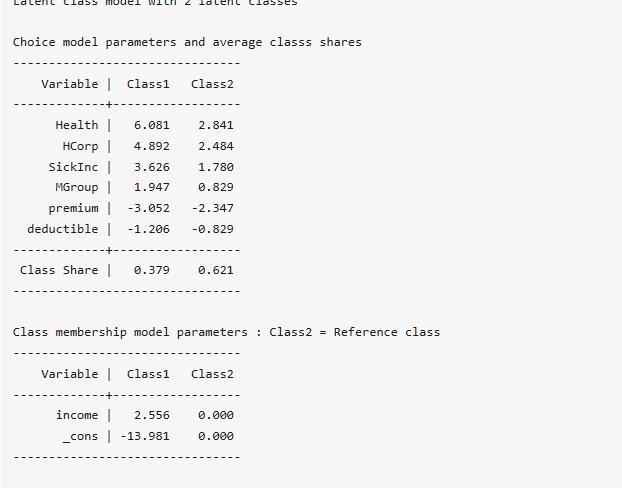
上表顯示了潛類別logit模型以類別2為參考類別,并報告了每個類別的比例,由于我們更關心參數估計,故上面的結果就不作過多的解釋,下面將展示參數估計結果:
. lclogitml, iter(10)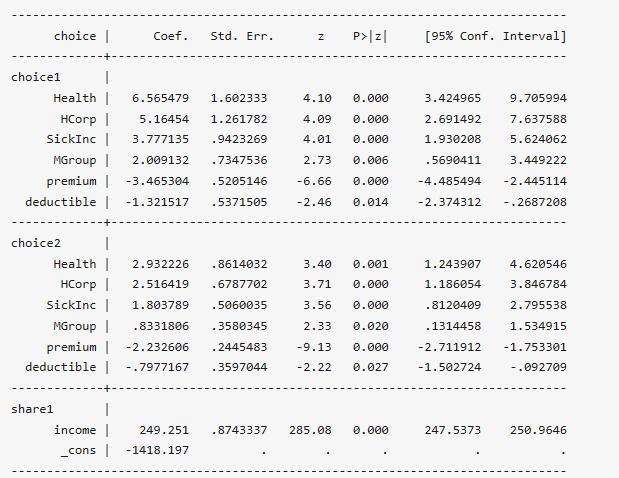
參數估計結果顯示,無論是在類別1還是類別2,如果其他解釋變量的取值相同(premium、deductible),則個人最有可能選擇Health保險方案;相較于類別2,類別1的群體受保費和免賠額的影響更大。另外,一個方案的保費和免賠額越高,則選擇該方案的概率越低,這與條件logit模型估計的結果一致。此外,相比于類別2,類別1的人群更有可能是年收入更高的人群。同樣的,我們采取exp(B)的方式計算風險比,這里就不加以演示了。
4 結語
本文通過實例詳細地介紹了條件logit模型、混合logit模型、隨機參數logit和潛類別logit模型的stata實現過程,尤其介紹了隨機參數logit和潛類別logit兩種異質性模型,希望能對讀者在利用這些模型做研究時提供幫助。值得注意的是,本文并未比較各模型的優劣,在實際應用中可以采用偽R方、預測準確性和BIC等指標選取最佳模型。此外,以作者的經驗來看,stata提供的命令雖然簡單,但是局限性也較多,有興趣的讀者可以考慮用Nlogit軟件實現各種離散模型的估計。如果各位讀者有興趣,后續可以專門寫一篇用Nlogit軟件估計非線性效用函數的隨機參數logit模型和有序隨機參數logit模型的推文。
5 參考文獻
[1] Train K. Discrete Choice Methods With Simulation [M]. Second edition. Cambridge: Cambridge University Press, 2009.
[2] Mannering F L, Bhat C R. Analytic methods in accident research: methodological frontier and future directions [J]. Analytic Methods in Accident Research, 2014, 1: 1-22.
[3] Pacifico D , Yoo H I . Lclogit: A Stata Command for Fitting Latent-Class Conditional Logit Models via the Expectation-Maximization Algorithm[J]. Stata Journal Promoting Communications on Statistics & Stata, 2013, 13(3):625-639.
[4] StataCorp. 2019.Stata choice models reference manual release 16. College Station, TX: StataCorp LLC.
[5] 陳強. 高級計量經濟學及stata應用(第二版),2013.
學習Nlogit軟件的參考書目:
[1 ]Hensher D A, Rose J M , Greene W H. Applied Choice Analysis [M]. Second edition. Cambridge: Cambridge University Press, 2015.
[2] Greene W H.2016. NLOGIT version 6 reference guide[S]. Plainview, NY: Econometric Software.
6 完整代碼
use https://www.stata-press.com/data/r16/inschoice//展示前10行數據list in 1/10, sepby(id) abbreviate(10)//描述性統計sum id premium deductible income insurance choice//生成方案的虛擬變量gen Health=0gen HCorp=0gen SickInc=0gen MGroup=0gen MoonHealth=0replace Health=1 if insurance==1replace HCorp=1 if insurance==2replace SickInc=1 if insurance==3replace MGroup=1 if insurance==4replace MoonHealth=1 if insurance==5//條件logit模型回歸,以方案5(MoonHealth)為參考類別clogit choice Health HCorp SickInc MGroup premium deductible,group(id) nologclogit choice Health HCorp SickInc MGroup premium deductible,group(id) nolog or//混合logit模型回歸,以方案5(MoonHealth)為參考類別asclogit choice premium deductible,case(id) alternatives(insurance) base(5) nolog//混合logit模型回歸,以方案5(MoonHealth)為參考類別,加入income,并求orasclogit choice premium deductible,case(id) alternatives(insurance) base(5) casevars(income) nolog or//隨機參數logit模型,Halton抽樣cmmixlogit choice, random(deductible premium) casevars(income) basealternative(5) intmethod(Halton) intpoints(1000)display(0.8484104/ 0.4390417)display(0.8561866/ 0.4157747 )marginsmargins, at(deductible=generate(deductible*1.01)) alternative(Health)//確定最優的潛類別logit模型分類數目forvalues c = 2/5 { lclogit choice premium deductible,group(id) id(id) nclasses(`c') membership(income) seed(123) matrix b = e(b) matrix ic = nullmat(ic) \ `e(nclasses)', `e(ll)', `=colsof(b)', `e(caic)', `e(bic)'}matrix colnames ic = "Classes" "LLF" "Nparam" "CAIC" "BIC"matlist ic, name(columns)//估計二類潛類別logit模型lclogit choice Health HCorp SickInc MGroup premium deductible,group(id) id(id) nclasses(2) membership(income) seed(123)lclogitml, iter(10)