數據分析方法(SPSSAU 數據分析 :logit回歸分析步驟匯總)
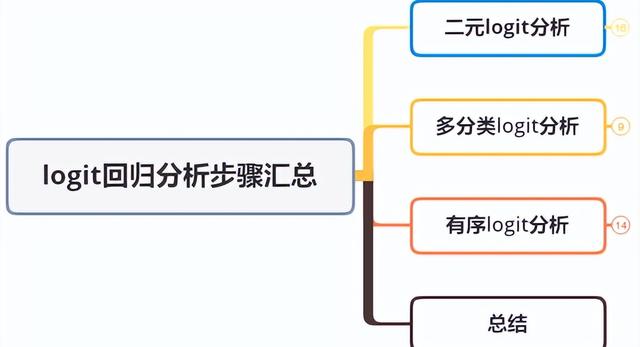
Logit回歸分析用于研究X對Y的影響,并且對X的數據類型沒有要求,X可以為定類數據(可以做虛擬變量設置),也可以為定量數據,但要求Y必須為定類數據,并且根據Y的選項數,使用相應的數據分析方法。logit回歸分析一般可分為三類,分別是二元logit回歸、多分類logit回歸、有序logit回歸,三類logit回歸區別如下:

二元logit分析
1.基本說明
二元Logit回歸分析用于研究X對于Y的影響關系,其中X通常為定量數據(如果X為定類數據,一般需要做虛擬(啞)變量設置)
Y為二分類定類數據,(Y的數字一定只能為0和1)例如愿意和不愿意、是和否等。
2.數據處理
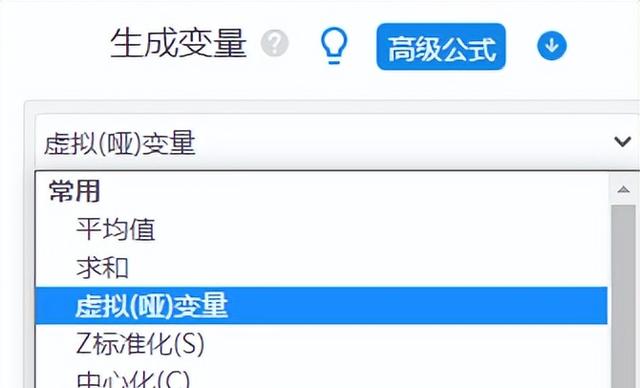
(1)如果X是定類數據,比如性別或學歷等。那么就需要首先對它們做虛擬啞變量處理,使用SPSSAU“數據處理”-“生成變量”功能。操作如下圖:
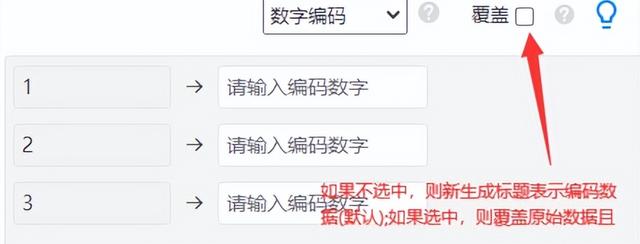
(2)因變量Y只能包括數字0和1,如果因變量的原始數據不是這樣,那么就需要數據編碼,設置成0和1,使用SPSSAU“數據處理”-“數據編碼”功能,操作如下圖:
3.SPSSAU上傳數據
(1)登錄賬號后進入SPSSAU頁面,點擊右上角“上傳數據”,將處理好的數據進行“點擊上傳文件”上傳即可。

(2)拖拽分析項
在“進階方法”模塊中選擇“二元Logit”方法,將Y定類變量放于上方分析框內,X定類/定量變量放于下方分析框內,點擊“開始分析”即可。
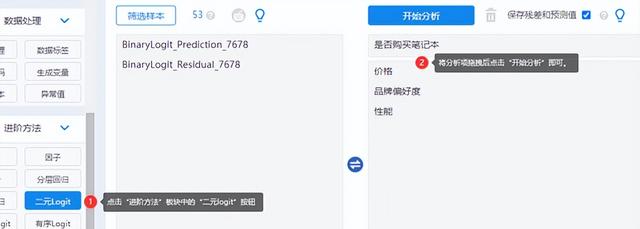
可以勾選“保存殘差和預測值” 將殘差和預測值保存起來,可用于進—步分析使用。
4.分析前提示
(1)如果X為定類數據,此時可以考慮使用交叉卡方分析去研究X和Y的關系。
(2)如果X非常多(比如超過10個),此時可以先對定類的X與Y進行卡方分析,對定量的X與Y進行方差分析(或t檢驗),先看有沒有差異關系,將最終有差異關系的X放入二元Logit回歸模型中,這樣X會較少,并且X與Y均有差異關系,也更可能有影響關系,此時二元Logit回歸模型的預測準確率會更高。
如果例子里面自變量X較少,模型本身并不復雜,可忽略此步驟即可,直接進行二元logistic回歸分析。
5.SPSSAU分析
背景:研究影響用戶購買某品牌筆記本電腦的因素,其中0代表否,1代表是(僅供案例分析)。
(1)二元Logit回歸分析基本匯總
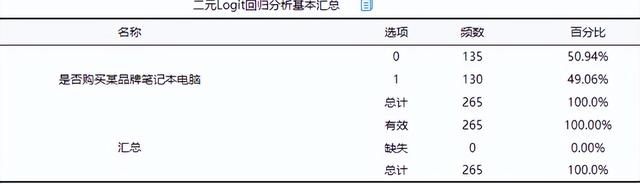
將價格, 品牌偏好度, 性能作為自變量,而將是否購買某品牌筆記本電腦作為因變量進行二元Logit回歸分析,從上表可以看出,總共有265個樣本參加分析,并且沒有缺失數據。
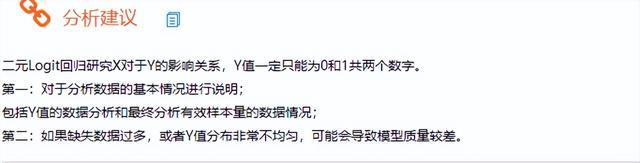
(2)二元Logit回歸模型似然比檢驗結果


首先對模型整體有效性進行分析,從上表可知:此處模型檢驗的原定假設為:是否放入自變量(價格, 品牌偏好度, 性能)兩種情況時模型質量均一樣;這里p值小于0.05,因而說明拒絕原定假設,即說明本次構建模型時,放入的自變量具有有效性,本次模型構建有意義。
(3)二元Logit回歸分析結果匯總
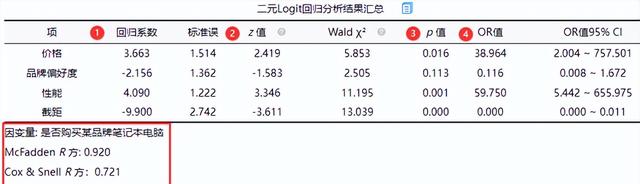
從上表可知,將價格, 品牌偏好度, 性能共3項為自變量,而將是否購買某品牌筆記本電腦作為因變量進行二元Logit回歸分析,模型公式為:ln(p/1-p)=-9.900 + 3.663*價格-2.156*品牌偏好度 + 4.090*性能(其中p代表是否購買某品牌筆記本電腦為1 的概率,1-p代表是否購買某品牌筆記本電腦為0的概率)。最終具體分析可知:
價格的回歸系數值為3.663,并且呈現出0.05水平的顯著性(z=2.419,p=0.016<0.05),意味著價格會對是否購買某品牌筆記本電腦產生顯著的正向影響關系。以及優勢比(OR值)為38.964,意味著價格增加一個單位時,是否購買某品牌筆記本電腦的變化(增加)幅度為38.964倍。
品牌偏好度的回歸系數值為-2.156,但是并沒有呈現出顯著性(z=-1.583,p=0.113>0.05),意味著品牌偏好度并不會對是否購買某品牌筆記本電腦產生影響關系。
性能的回歸系數值為4.090,并且呈現出0.05水平的顯著性(z=3.346,p=0.001<0.05),意味著性能會對是否購買某品牌筆記本電腦產生顯著的正向影響關系。以及優勢比(OR值)為59.750,意味著性能增加一個單位時,是否購買某品牌筆記本電腦的變化(增加)幅度為59.750倍。
總結分析可知:價格, 性能共2項會對是否購買某品牌筆記本電腦產生顯著的正向影響關系。但是品牌偏好度并不會對是否購買某品牌筆記本電腦產生影響關系。
此外Logit回歸時會提供三個R 方值(分別是McFadden R 方、Cox & Snell R 方和Nagelkerke R 方),此3個R 方均為偽R 方值,其值越大越好,但其無法非常有效的表達模型的擬合程度,意義相對交小,而且多數情況此3個指標值均會特別小,研究人員不用過分關注于此3個指標值。一般報告其中任意一個R方值指標即可。
(4)二元Logit回歸預測準確率匯總
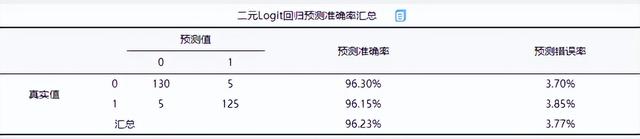
通過模型預測準確率去判斷模型擬合質量,從上表可知:研究模型的整體預測準確率為96.23%,模型擬合情況良好。當真實值為0時,預測準確率為96.30%;另外當真實值為1時,預測準確率為96.15%。
(5)Hosmer-Lemeshow擬合度檢驗

Hosmer-Lemeshow擬合度檢驗用于分析模型擬合優度情況,從上表可知:此處模型檢驗的原定假設為:模型擬合值和觀測值的吻合程度一致;這里p值大于0.05(卡方值為3.109,p=0.927>0.05),因而說明接受原定假設,即說明本次模型通過HL檢驗,模型擬合優度較好。
(6)模型預測
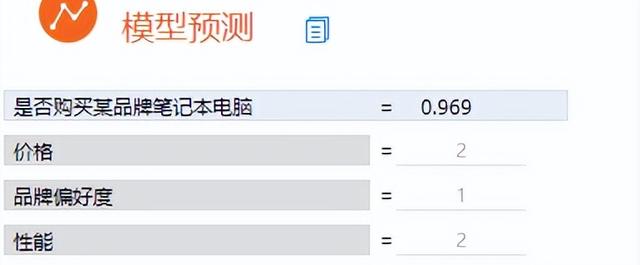
將價格、品牌偏好度以及性能輸入該模型就能夠預測消費者是否購買某品牌筆記本電腦。
(7)模型結果圖
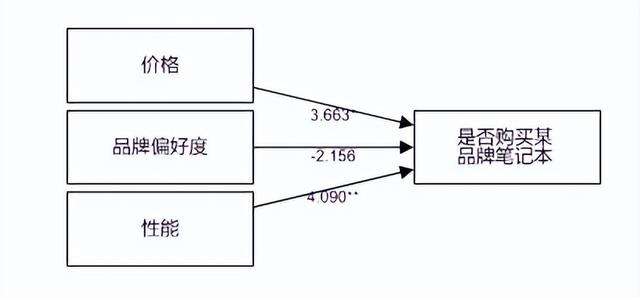
可以更直觀的看見自變量與因變量的關系。
(8)coefPlot
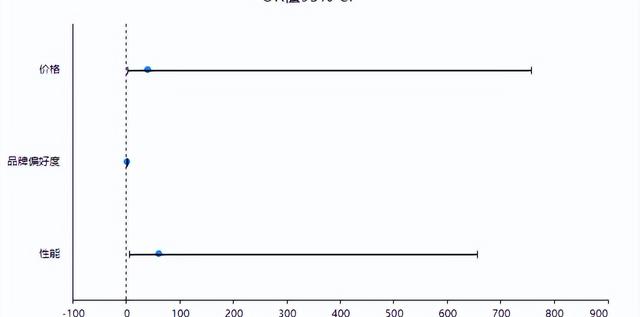
coefPlot展示具體的回歸系數值和對應的置信區間,可直觀查看數據的顯著性情況,如果說置信區間包括數字0則說明該項不顯著,如果置信區間不包括數字0則說明該項呈現出顯著性。
6.其它說明
(1)二元logit回歸提示數據質量異常?
如果出現此提示,建議按以下步驟進行檢驗。
第一:將所有分析項(X和Y全部一起)做相關分析,查看是否有相關系數非常低或 者非常高的項;如果非常低(比如小于0.1)說明完全沒有關聯關系,非常高(比如 大于0.8)說明共線性問題嚴重,將此類自變量移除出去,再次分析就好;
第二:檢查因變量Y的分布情況,因變量Y僅僅兩個數字0和1,如果分布嚴重不均勻(比如100個樣本中僅5個樣本為0,95個為1),有可能出現模型無法收斂最后無法輸出結果;
第三:自變量中放入虛擬變量,比如學歷有5項,虛擬變量出來為5項,5項全部都放入了模型,這一定會出錯;
第四:分析樣本量過小,比如分析項有10個,但分析樣本量僅20個。
(2)Y值只能為0或1?
二元logistic回歸研究X對Y的影響,Y為兩個類別,比如是否愿意,是否喜歡,是否購買等,數字一定有且僅為2個,分別是0和1。如果不是這樣就會出現此類提示,可使用SPSSAU頻數分析進行檢查,并且使用數據處理-數據編碼功能進行處理成0和1。
(3)crude OR和adjusted OR值?
在SPSSAU中進行二元Logit回歸,如果放入一個X,得到的OR值即為crude OR,如果放入該X的時候還放入其余的控制項,并且得到對應該X的OR值,就稱為adjusted OR值。
多分類logit分析
1.基本說明
只要是logit回歸,都是研究X對于Y的影響,區別在于因變量Y上,如果Y有多個選項,并且各個選項之間不具有對比意義,例如,1代表“黑龍江省”,2代表“云南省”,3代表“四川省”,4代表“陜西省”,數值僅代表不同類別,數值大小不具有對比意義,那么應該使用多分類Logit回歸分析。
2.數據要求與處理
如果說因變量Y的類別個數很多,比如為10個,此時建議時對類別進行組合下,盡量少的減少類別數量,便于后續進行分析。此步驟可通過SPSSAU數據處理模塊的數據編碼功能完成。
如果說自變量X是定類數據,那么可對X進行虛擬啞變量處理,使用SPSSAU數據處理模塊的生成變量功能。其實定類數據在做影響關系研究時,通常都會做虛擬啞變量處理。
3.SPSSAU上傳數據
(1)登錄賬號后進入SPSSAU頁面,點擊右上角“上傳數據”,將處理好的數據進行“點擊上傳文件”上傳即可。

(2)拖拽分析項
在“進階方法”模塊中選擇“多分類Logit”方法,將Y定類變量放于上方分析框內,X定類/定量變量放于下方分析框內,點擊“開始分析”即可。
可以勾選“保存預測類別” 將預測值保存起來,可用于進—步分析使用。
4.SPSSAU分析
背景:研究影響手機偏好的因素(僅供案例分析)。
(1)多分類Logistic回歸分析基本匯總
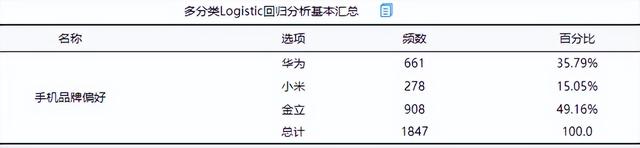
將年齡, 學歷, 性別作為自變量,而將手機品牌偏好作為因變量進行多分類Logit回歸分析,從上表可以看出,總共有1847個樣本參加分析。
(2)多分類Logistic回歸模型似然比檢驗


此處模型檢驗的原定假設為:是否放入自變量(年齡, 學歷, 性別)兩種情況時模型質量均一樣;這里p值小于0.05,因而說明拒絕原定假設,即說明本次構建模型時,放入的自變量具有有效性,本次模型構建有意義。
(3)多分類Logistic回歸分析結果匯總
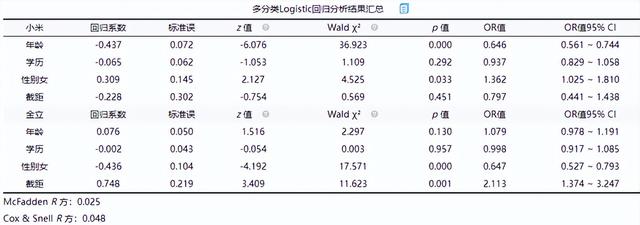
上表格中可以看出年齡和性別的p值<0.05均呈現顯著性,以下具體說明:
女性的回歸系數值為0.309,并且呈現出0.05水平的顯著性(z=2.127,p=0.033<0.05),這說明女性更加偏好于小米手機。原因:在多分類logit回歸中,SPSSAU將因變量Y的第1項(此處為華為手機)作為參照項。那么性別女呈現出正向影響,就說明相對于華為手機來講,女性明顯更加偏好于小米手機。
相對華為手機來講,年齡的回歸系數值為-0.437,并且呈現出0.01水平的顯著性(z=-6.076,p=0.000<0.01),負向影響,即說明年齡越大用戶越偏好于華為手機。
金立手機分析結果可以看出女性相對于更喜歡華為手機,年齡越大用戶越偏好于金立手機。

此外Logit回歸時會提供三個R 方值(分別是McFadden R 方、Cox & Snell R 方和Nagelkerke R 方),此3個R 方均為偽R 方值,其值越大越好,但其無法非常有效的表達模型的擬合程度,意義相對交小,而且多數情況此3個指標值均會特別小,研究人員不用過分關注于此3個指標值。一般報告其中任意一個R方值指標即可。
(4)預測準確率匯總
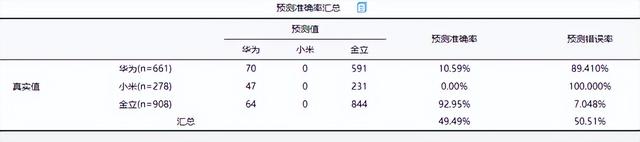
通過模型預測準確率去判斷模型擬合質量,從上表可知:研究模型的整體預測準確率為49.49 %,模型擬合情況一般。
5.其它說明
(1)提示“Y的選項過少或過多”?
如果出現此提示,意味著因變量Y的選項不符合多分類logit回歸分析要求,通常情況下因變量Y的分類個數應該介于3~8個之間。
1)研究者可使用SPSSAU頻數分析功能進行查看因變量Y的選項個數情況;
2)如果選項個數過多需要進行合并處理等,可使用SPSSAU【數據處理->數據編碼】功能操作。
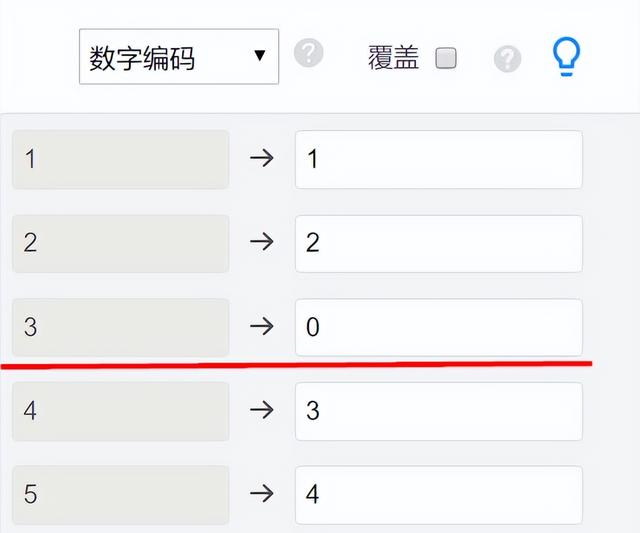
(2)參照項或參考項設置問題?
進行多分類Logit時, SPSSAU默認以第一項【即數字最小的那項】作為參考項。如果需要進行改變,可使用【數據處理->數據編碼】功能進行設置,將參考項的數字設為最小即可,如下圖所示(原本以1作為參考項,現在改為3作為參考項,將3設置為數字最小0即可,當然設置其它更小值比如-1也可以):
有序logit分析
1.基本說明
只要是logit回歸,都是研究X對于Y的影響,區別在于因變量Y上,如果Y有多個選項,并且各個選項之間具有對比意義,例如:1代表不滿意,2代表一般,3代表滿意就可以使用有序logit回歸分析。
2.SPSSAU上傳數據
(1)登錄賬號后進入SPSSAU頁面,點擊右上角“上傳數據”,將處理好的數據進行“點擊上傳文件”上傳即可。

(2)拖拽分析項
在“進階方法”模塊中選擇“有序Logit”方法,將Y定類變量放于上方分析框內,X定類/定量變量放于下方分析框內,點擊“開始分析”即可。
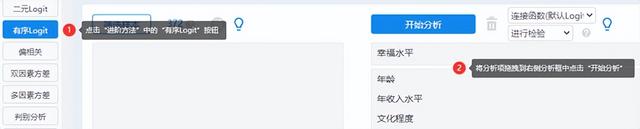
3.參數選擇
(1)接連函數選擇
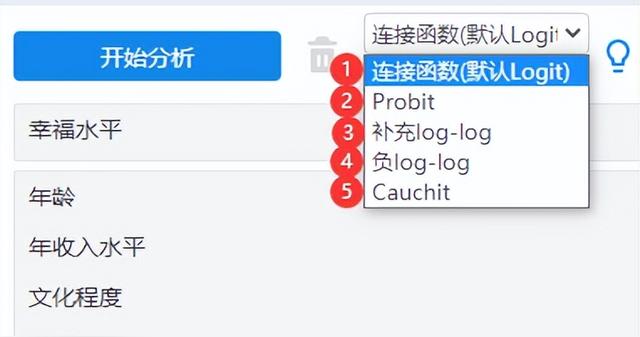
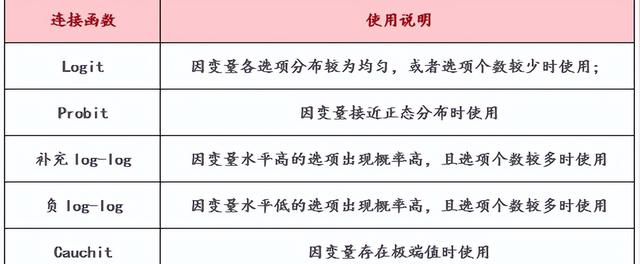
(2)平行性檢驗選擇
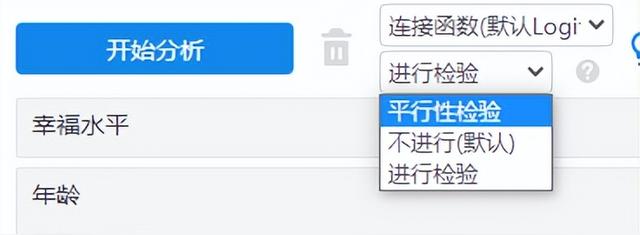
用于檢驗各回歸方程相互平行。如果不滿足平行性檢驗(或出現異常),建議使用多分類Logit回歸即可。
4.SPSSAU分析
背景:究民眾幸福度影響因素,包括性別,年齡,學歷和年收入水平共4個潛在的影響因素對于幸福水平的影響情況。
(1)有序Logistic回歸分析因變量頻數分布

本次有序Logit回歸模型將性別(女性作為參照項), 年齡, 學歷, 年收入水平作為自變量,將幸福水平作為因變量進行有序logistic回歸分析,從上表可知:幸福水平共分為三個類別,分布較為均勻,其中比較幸福這一類別的占比較低為20.70%。
(2)有序Logistic回歸模型平行性檢驗

首先對模型進行平行性檢驗,從上表可知:平行性檢驗的原假設是各回歸方程互相平行,分析顯示接受原假設(χ=1.858,p =0.762> 0.05),因而說明本次模型通過平行性檢驗,模型分析結論可信,可繼續進一步的分析。
如果沒有通過平行性檢驗則有以下建議:
改用多分類logit回歸;換個方法,因為一般可使用有序logit回歸的數據也可以使用多分類logit回歸分析;
改用線性回歸;可考慮換成線性回歸分析嘗試;
改變連接函數;選擇更適合的連接函數;
將因變量的類別選項進行一些合并處理等,使用SPSSAU數據處理->數據編碼功能。
一般來說,有序logit回歸有一定的穩健性,即平行性檢驗對應的p值接近于0.05時,可考慮直接接受有序logit回歸分析的結果。
有序Logistic回歸模型似然比檢驗

首先對模型整體有效性進行分析(模型似然比檢驗),從上表可知:此處模型檢驗的原定假設為:是否放入自變量(年齡, 年收入水平, 文化程度, 性別男)兩種情況時模型質量均一樣;分析顯示拒絕原假設(chi=62.510,p=0.000<0.05),即說明本次構建模型時,放入的自變量具有有效性,本次模型構建有意義。
補充說明:SPSSAU還提供AIC和BIC這兩個指標值,如果模型有多個,而且希望進行模型之間的優劣比較,可使用此兩個指標,此兩個指標是越小越好。具體可直接查看SPSSAU的智能分析和分析建議即可。
有序Logistic回歸模型分析結果匯總
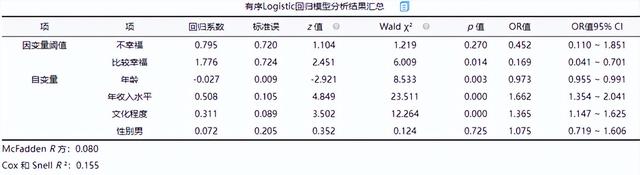
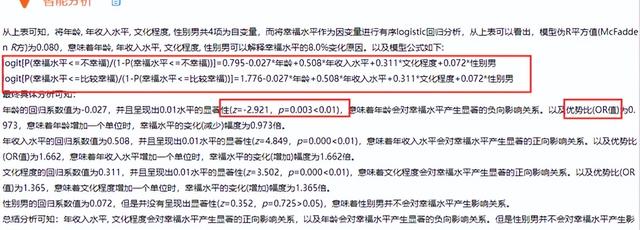
有序Logistic回歸模型預測準確率

通過模型預測準確率去判斷模型擬合質量,從上表可知:研究模型的整體預測準確率為55.65%,模型擬合情況較差。建議剔除掉無關的自變量,或者對自變量進行數據編碼組合重新處理后再次進行分析,得到更佳的分析結果,同時可考慮使用多分類logit回歸進行分析。
模型結果圖
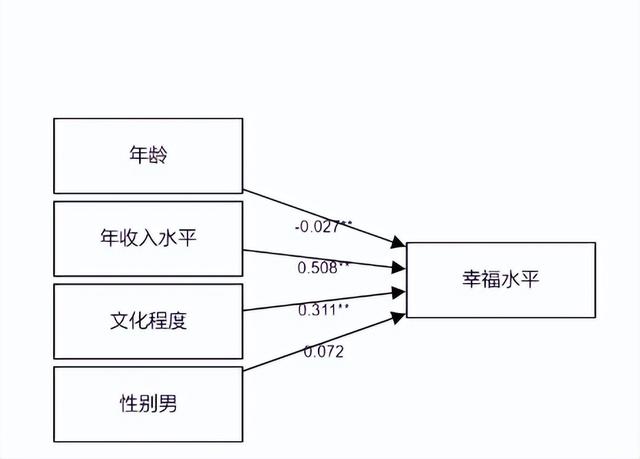
可以更直觀的看見自變量與因變量的關系(基于回歸系數的基礎上)。
coefPlot
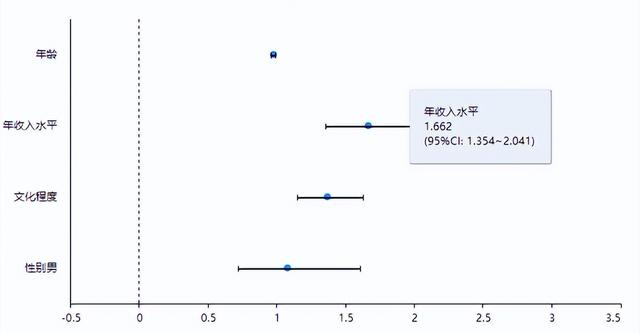
coefPlot展示具體的回歸系數值和對應的置信區間,可直觀查看數據的顯著性情況,如果說置信區間包括數字0則說明該項不顯著,如果置信區間不包括數字0則說明該項呈現出顯著性。可以看到年齡、年收入水平、文化程度以及性別男的or值以及95%CI。
5.其它說明
(1)OR值的意義
OR值=exp(b)值,即回歸系數的指數次方,該值在醫學研究里面使用較多,實際意義是X增加1個單位時,Y的增加幅度。如果僅僅是研究影響關系,該值意義較小。
(2)z 值的意義是什么?
z 值=回歸系數/標準誤,該值為中間過程值無意義,只需要看p 值即可。有的軟件會提供wald值(但不提供z 值,該值也無實際意義),wald值= z 值的平方。
總結
本篇文章包括二元logit回歸步驟分析、多分類logit回歸步驟分析、有序logit回歸步驟分析,其中二元Logit回歸分析時,首先可以分析p 值,如果此值小于0.05,說明具有影響關系,接著再具體研究影響關系情況即可,比如是正向影響還是負向影響關系等;除此之外,還可以寫出二元Logit回歸分析的模型構建公式,以及模型的預測準確率情況等。
對于多分類Logit回歸分析模型的具體情況進行分析,首先分析p 值,如果此值小于0.05,說明X對于Y有影響關系,接著再具體研究影響關系情況即可,比如是正向影響還是負向影響關系等;除此之外,還可以寫出回歸模型構建公式,以及模型的預測準確率情況等。
有序Logit回歸分析時,首先進行模型平行性檢驗,如果p 值大于0.05,說明滿足平行性檢驗,如果p 值小于0.05,說明不滿足平行性檢驗,此時SPSSAU建議使用多分類Logit回歸分析;滿足平行性檢驗后,接著再具體研究影響關系情況即可,比如是正向影響還是負向影響關系等;除此之外,還可以寫出有序Logit回歸分析的模型構建公式,以及模型的預測準確率情況等。