特征工程常用方法(特征工程中的縮放和編碼的方法總結)
數據預處理是機器學習生命周期的非常重要的一個部分。 特征工程又是數據預處理的一個重要組成, 最常見的特征工程有以下一些方法:
編碼
縮放
轉換
離散化
分離
等等
在本文中主要介紹特征縮放和特征編碼的主要方法。
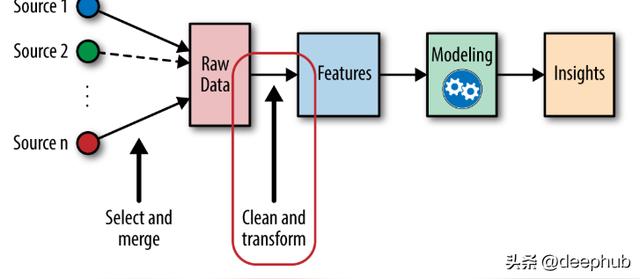
特征縮放
特征縮放是一種在固定范圍內對數據中存在的獨立特征進行標準化的技術。有些機器學習模型是基于距離矩陣的,例如:k - nearest - neighbors, SVM和Neural Network。對于這些模型來說,特性縮放是非常重要的,特別是當特性的范圍非常不同的時候。范圍較大的特征對距離計算的影響較大。
標準化 Standarization
數據的標準化是將數據按比例縮放,使之落入一個小的特定區間,把數據轉換為統?的標準。z-score標準化,即零-均值標準化(常用方法)
標準化(或z分數歸一化)縮放后,特征就變為具有標準正態分布,具有μ= 0和σ= 1,其中μ均值,σ是平均值的標準差。
通過標準化約68%的值介于-1和1之間。
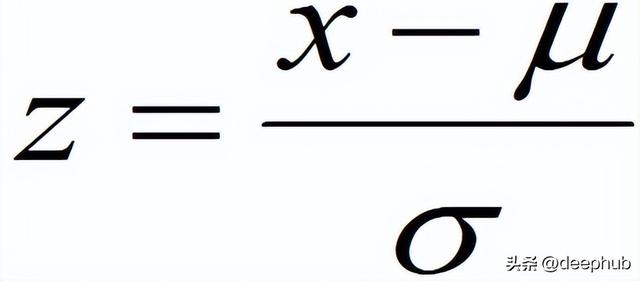
from sklearn.preprocessing import StandardScalerscale = StandardScaler().fit(data)scaled_data = scale.transform(data)規范化(歸一化)Normalization
規范化是把數據變為(0,1)之間的小數。主要是為了方便數據處理,將數據映射到0~1范圍之內,可以使處理過程更加便捷、快速。
規范化經常被用作機器學習數據準備的一部分。規范化的目標是更改數據集中數值列的值,以使用通用的刻度,而不會扭曲值范圍的差異或丟失信息
最常見的方法是最小-最大縮放,公式如下:
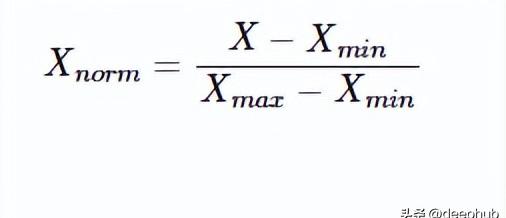
from sklearn.preprocessing import MinMaxScaler norm = MinMaxScaler().fit(data)transformed_data = norm.transform(data)將特征的每個值除以最大值是規范化的另一種方法。 它通常與稀疏數據一起使用(例如圖像)。
data_norm = data['variable']/np.max(data['variable'])另一種規范化方法是RobustScalar,用于處理異常值問題。RobustScalar使用四分位范圍(IQR),因此它對異常值是穩健的。
from sklearn.preprocessing import RobustScalerrob = RobustScaler().fit(data)data_norm = rob.transform(data)標準化與規范化的區別
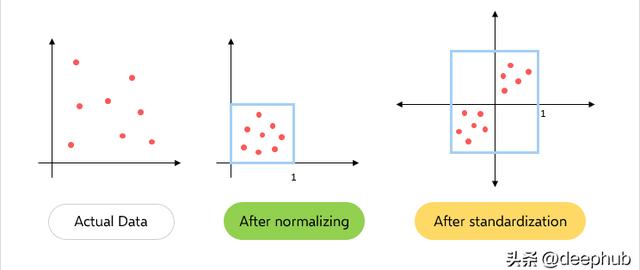
在規范化中只更改數據的范圍,而在標準化中會更改數據分布的形狀。
規范化將這些值重新縮放到[0,1]的范圍內。在所有參數都需要具有相同的正刻度的情況下是非常有效的。但是數據集中的異常值會丟失。
而在標準化中,數據被縮放到平均值(μ)為0,標準差(σ)為1(單位方差)。
規范化在0到1之間縮放數據,所有數據都為正。標準化后的數據以零為中心的正負值。
如何選擇使用哪種縮放方法呢?
當數據具有識別量表并且使用的算法不會對數據的分布,比如K-Nearealt鄰居和人工神經網絡時,規范化是有用的。
當數據是識別量表時,并且使用的算法確實對具有高斯(正態)分布的數據進行假設,例如如線性回歸,邏輯回歸和線性判別分析標準化很有用。
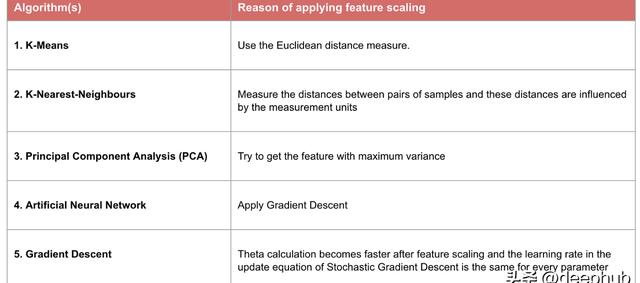
雖然是這么說,但是使用那種縮放來處理數據還需要實際的驗證,在實踐中可以用原始數據擬合模型,然后進行標準化和規范化并進行比較,那個表現好就是用那個,下圖是需要使用特征縮放的算法列表:
特征編碼
上面我們已經介紹了針對數值變量的特征縮放,本節將介紹針對分類變量的特征編碼,在進入細節之前,讓我們了解一下特征編碼的不同類型。
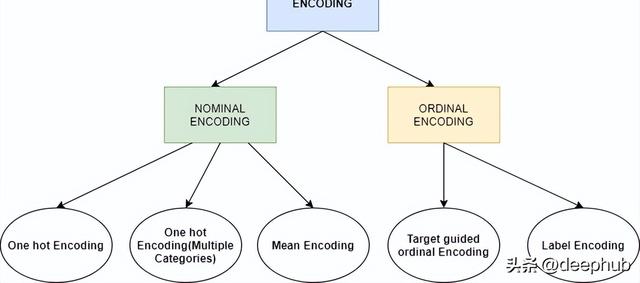
NOMINAL CATEGORICAL是我們不需要關心排列或順序的分類變量。例如性別,產品類別,國家地區,這些分類變量沒有順序的概念。
ORDINAL CATEGORICAL是序數類別,這里的類別還包含了順序的信息,比如我們考試的分數 ,優、良、中、差,優是最好的,差是最不好的。或者是我們的教育程度,小學,中學,大學,碩士,也是按照順序排列的。
了解了上面的類型后,我們開始進行特征編碼的介紹:
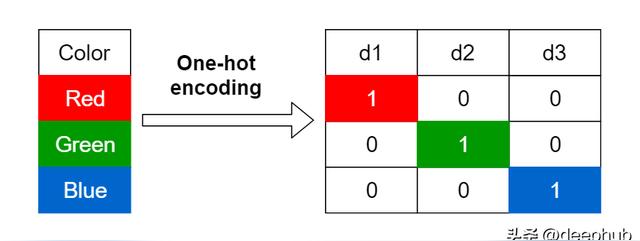
獨熱編碼(ONE HOT)
我們有一個包含3個分類變量的列,那么將在一個熱編碼中為一個分類變量創建每個熱量編碼3列。
獨熱編碼又稱一位有效編碼。其方法是使用 N位 狀態寄存器來對 N個狀態 進行編碼,每個狀態都有它獨立的寄存器位,并且在任意時候,其中只有一位有效。
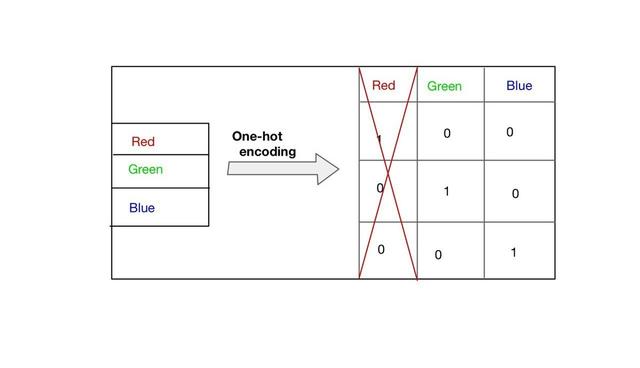
啞變量陷阱
啞變量陷阱是指一般在引入虛擬變量時要求如果有m個定性變量,在模型中引入m-1個虛擬變量。否則如果引入m個虛擬變量,就會導致模型解釋變量間出現完全共線性的情況。
所以上面的例子中,我們可以跳過任何列我們這里選擇跳過第一列“red”
獨熱編碼雖然簡單,但是頁有非常明顯的缺點:
假設一列有100個分類變量。現在如果試著把分類變量轉換成啞變量,我們會得到99列。這將增加整個數據集的維度,從而導致維度詛咒。
所以基本上,如果一列中有很多分類變量我們就不應該用這種方法。這里有一個簡單的解決辦法,只考慮那些重復次數最多的類別,例如只考慮前10個數量最多的類別,并只對這些類別應用編碼。
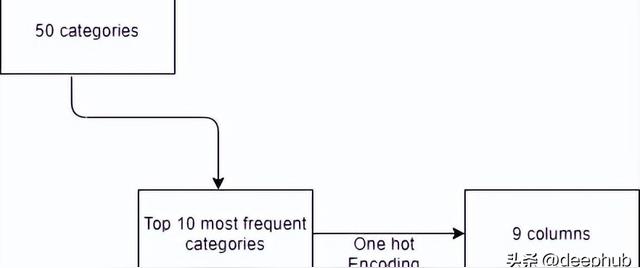
from sklearn.preprocessing import OneHotEncoderohe = OneHotEncoder(drop='first',sparse=False,dtype=np.int32)counts = df['brand'].value_counts()df['brand'].nunique()threshold = 100repl = counts[counts <= threshold].indexpd.get_dummies(df['brand'].replace(repl, 'uncommon')).sample(5)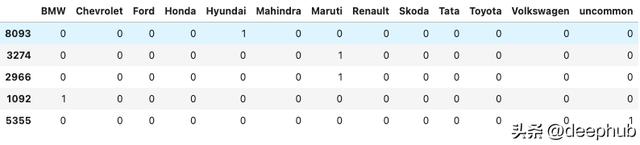
序列化標簽編碼(ORDINAL ENCODING)
這種編碼方式僅用于序數類別,因為排名是根據類別的重要性來提供的。例如下表PHD被認為是最高的學位,所以給了它最高的標簽。
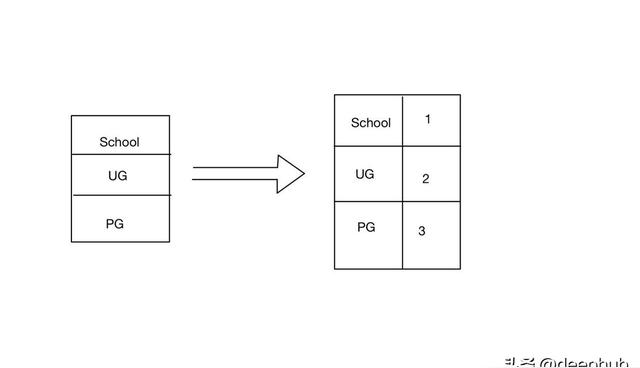
from sklearn.preprocessing import OrdinalEncoderoe = OrdinalEncoder(categories=[['Poor','Average','Good'],['School','UG','PG']])oe.fit(X_train)X_train = oe.transform(X_train)標簽編碼(LABEL ENCODING)
標簽編碼與序列化標簽編碼是相同的,但是它編碼后的數字并不包含序列的含義。
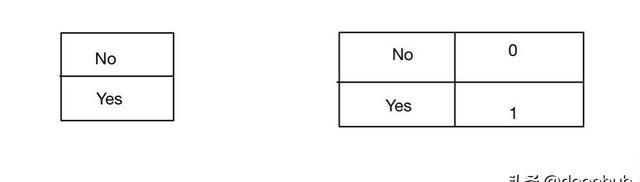
from sklearn.preprocessing import LabelEncoderle = LabelEncoder()le.fit(y_train)le.classes_目標指導的序列化編碼
這種方法根據輸出計算每個分類變量的平均值,然后對它們進行排名。 如下表所示
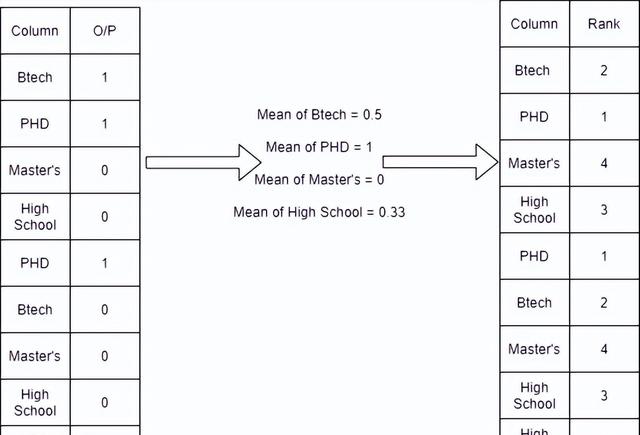
在序數類別中,我們可以應用這項技術,因為我們最后輸出的結果包含了順序的信息。
平均數編碼(MEAN ENCODING)
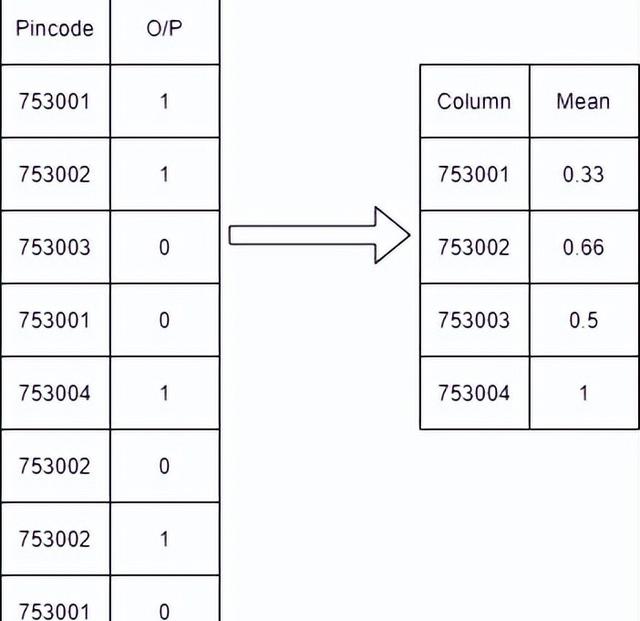
在這種方法將根據輸出將類別轉換為其平均值。在有很多特定列的分類變量的情況下,可以應用這種類型的方法。
例如,下面的表中,我們根據特征的類別進行分組,然后求其平均值,并且使用所得的平均值來進行替換該類別
作者:sumit sah